
WebRTC Bugs and Where to Find Them
Also for the most basic use cases, WebRTC is a complex technology, with lots of moving parts and involved elements and parties working together at the same time, so when a WebRTC connection is not working properly, or directly it can not be created, there’s a series of not-so-obvious usual reasons that can make it fail. We are going to analyze some of the most common ones, and when possible, see how we can fix them or find some alternatives solutions to minimize their impact.

Here we are assuming code is (mostly) well written, so failure points have not been previously considered nor taken measures against them. If that would be the case, they should be addressed to make the code more robust, of if that’s not possible, you can try to recover from them making the code more resilient, or at least notify the user so he can take the proper actions.
Environment
The easiest process to address problems is by discarding errors one at a time, starting with the obvious ones, that’s the reason why they usually gets totally overlooked and forgotten. And the most obvious ones, are in the environment where our app executes itself.
Testing
When debugging during the development stage, we can assume that environment is ok and that the problem is in our code, since we have already took time to prepare and config it (haven’t we?) so we go from small to bigger (that’s why unit tests are so much important, they allow for a quick and on-the-spot finding of the issues).
Permissions
But when something worked for us and later it doesn’t for others, or does it randomly, we need to address first our research to the environment configuration. One of the reasons can be lack of permissions in the platform, in case there are some (maybe company enabled) policies that prevent to use them. Lack of permissions can come from the application itself too, maybe the user doesn’t have permissions to access to that conference room, or could have not logged-in at all. In some cases, it can be a badly designed login or authentication mechanism the one that can prevent to use the application itself.
Connecting
Once we are sure to have the proper permissions, we can move to look for the issues in the connection itself, starting by checking if we can connect at all.
Discoverability
The first point to look for is about clients discoverability, it’s say, if we can announce ourselves to the others where we are, so they can be able to call us. This requires us to be able to connect to the discovery server itself (not to confuse with the signaling server, although they are related, and usually they are the same one), that can not be reachable if it’s down, or the server is not accessible, or networks are not properly configured, or there’s a DNS resolution problem… or just simply, there’s a bug in the server code that prevent to reply back to the client about their requests.
STUN and TURN servers
Once that we can discover other peers and they can discover us, connections can be established, just only usually they can’t be done directly. When both peers are in the same network (same wireless router, or LAN/Ethernet network, or directly accessible from the wide Internet by having our device a public IP - very uncommon and dangerous, by the way) that’s possible, but usually they are connected on different networks, for example from a domestic wifi network to another one at the other side of the world. This means their connection goes through multiple networks crossing firewalls and routers and NATs until both arrive to a common place. Later, they need to exchange the information about how connection can “go up” to the other peer from the common public network over the different private networks. This exchange of information is responsibility of the signaling server, and exchanged info is provided by STUN and TURN servers.
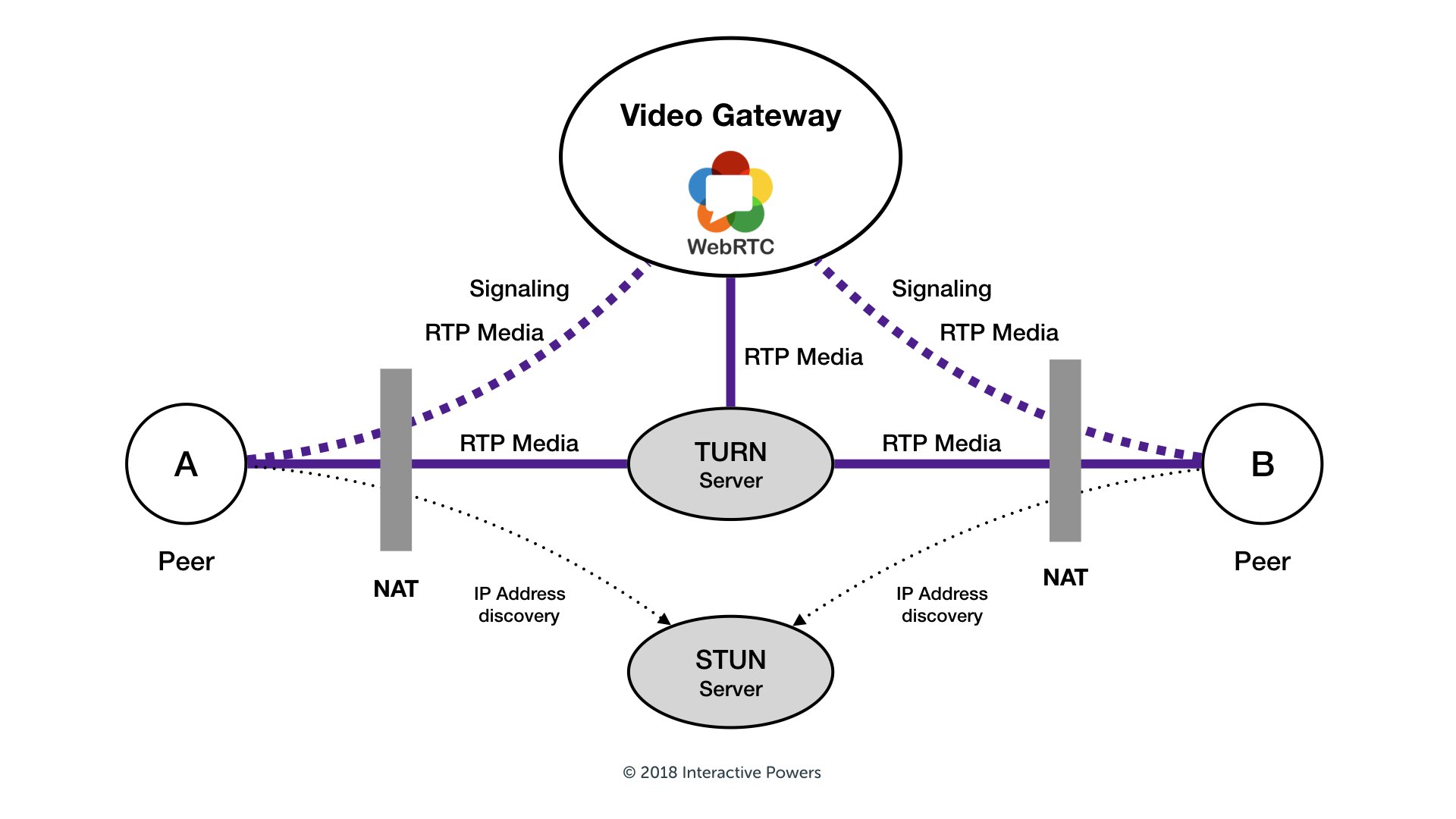
A STUN server provide a way for clients to know what’s their actual public IP and in what TCP/UDP port are they available, so they can send this information to the other peer. With that information, it’s possible to get a successful connection rate of about 80%. The reason for not achieving a 100% rate is because some network configurations like usage of simetric NATs prevent to do a direct connection, so in that case it’s needed to use a TURN server, that’s basically a tunnelling service. Due to this, all the data is going though that servers, so their costs are somewhat expensive due to high bandwidth usage in contrast to the STUN servers (in fact, there are several free ones, also some of them provided by Google, but it’s heavily recommended to use your own ones (both deployed by yourself or better contracted to an experienced provider) instead of use random STUN servers from internet. With a TURN server we can get up to a 95% of successful connection rate, and about a 85% on metropolitan areas.
Network infraestructure
What’s the issue why we can get a 100% rate also by using TURN servers? Not properly configured comporate networks, or usage of simetric NAT servers in both peers networks… or more frequently, packets filtering done by mobile cells network providers (on a personal note, I found a situation when using Vodafone mobile operator where I was able to communicate flawlessly on my own metropolitan area between my cell network and home connection, and the same others in other regions of Spain, but due to Vodafone usage of simetric NATs on their connection to other metropolitan areas “for security reasons”, I was able to receive their audio and video, but they were not able to receive mine, also when using properly configured TURN servers). In any case, having custom owned STUN and TURN servers are definitely needed for a production grade deployment.
This practices done by some mobile operators are due to various reasons: first of all, usage of WebRTC and VoIP applications prevents usage of voice minutes, that’s where mobile operators get their most revenues. That’s the same reason why usually they forbid usage of P2P communications (that WebRTC makes use of), initially due to P2P filesharing applications, and don’t provide unlimited data plans and in most cases also P2P, since data plans only incurs them on infraestructure maintenance and losses, and due to that costs, they doesn’t have enough infraestructure to provide unlimited data to all their clients the same way as in land lines and fiber without saturating their cell networks.
In addition of internet providers companies applying this kind of dubious network neutrality practices on their advantage, sometimes they are dictated to do so by gubernamental policies too. That’s the case of the United Arabic Emirates, where internet content is filtered and only government aproved VoIP apps can works flawlessly, or the infamous Great Firewall of China, that effectively force them to have their own goverment monitoried internet network. But these are not the only cases, since in the last years there has been (failed) efforts to apply similar restrictive legislations regarding network neutrality in other countries like Spain or United Kingdom. The only solutions in these cases are to get the application whitelisted on these goverment filters, or use tunneling solutions like VPN or Tor network, but since these kind of tools can easily override the government policies, they are also usually forbidden with huge fines.
Negotiation
When we are sure the connection is possible at transport level, it’s time to look if the connection itself can be agreed for between both parties.
Handshake timeouts
Connection values in a Session Description are very time constrained (about 5 minutes, but it can be less), so if there are (huge) delays in their transmission during the exchange of the Offer / Answer SDPs, they can timeout and became invalid, and connection can’t be established. This delay (and timeout) can happens more specially in the Answer SDPs if they don’t make use of Trickle ICE and need to collect all their ICE candidates before sending them back to the Offer sender.
One possible solution to reduce handshake time (not incompatible with using Trickle ICE) is to use a two-stages signaling, it’s said, use a regular signaling channel (for example, a WebSockets connection with JSON-RPC messages as transport protocol, or XMPP/Jingle protocol, or pigeons…) as first-stage signaling channel to create a minimal WebRTC connection with just a single WebRTC DataChannel transport, and later use it as a second-stage signaling channel specific between these two peers to extend the connection with any other media track we would like to use, and renegotiate the connection with it. This method is mostly used to reduce the server band-width costs to the minimum, since it’s being used only for the initial handshake, and specially when it’s expected that the connection will change frequently, with the addition that the changes will be faster since signaling will be direct between the peers. The point here is that it will also work on this use case because generation of the ICE Candidates to create a DataChannels are simpler and faster than for the full connection from the beginning.
An example of simple WebSockets based server that can be used as first-stage signaling channel is Schuko. I created it in 2012, and have beenusing it on several of the companies and projects I have been working during all these years, improving it from being just a application transparent and “poor’s man” tunnelling server and a simple “WebSockets extension cord”, to be capable as a full-fledged WebRTC discovery and signaling server, including automatic buffering and transparent reconnections.
When using Trickle ICE it could happen a related issue: sending the Offer and the Answer SDPs can be somewhat instantaneous since they only provide a description of the session, collecting the ICE candidates in background and sending them later. But since ICE candidates are specific for each one of sended tracks and independent between them, it can be possible that there are huge delays not only on their generation between peers, so one of them can last more time to start streaming to the other peer compared to doing it the other way, but also for example between associated audio and video tracks. This can leads to not being able to listen to a participant during some seconds after start seeing it (or not seeing it after start listening him), or in the worst case, maybe not listening (or seeing) him at all in any case if the ICE candidate negotiation for that track can not be done, or simply that it never arrives and give a timeout. This can happens for example if there’s some network change while doing the negotiation, although that would more probably make it fails the first negotiated one using the old network configuration.
Codecs negotiation
Regarding ICE candidates negotiation, it can also be possible that there would have not been an agreement if there’s no shared encoding formats. WebRTC clients try to negotiate and use the codecs that both has support for and that provides the highest quality, so this can be a strange situation since by the spec all WebRTC full-compliant clients must provide support for at least both the VP8 and H264 video codecs and Opus, PCMA and PCMU audio codecs, but it’s possible that a device with a customized WebRTC stack has disabled some of them or some of their functionality, or has added some other ones (web browsers and stock libraries, should be safe here).
More frequent it’s the case where there’s no agreement because one or both sides has put too much constraints about what codec formats to use (this was more common some years ago to improve compatibility with iOS devices before Safari 12.1 since Apple only had support for hardware accelerated H264 codec, preventing usage of software-only codecs due to increased battery usage), or constraints about codecs configuration like resolution or framerate not compatibles with the devices we are using. The way ICE candidates are being negotiated are from best to worse until they agreed on one of them (the best available one), so if all candidates are consumed without agree on use any of them, the connection can’t be done and the media track can’t be transmitted. In that case, the only solutions are to use APIs like MediaDevices.getSupportedConstraints() to detect the actual constraints supported by the device being used, or to add error handlers to detect both media device selection misconfigurations, and when all ICE candidates has been consumed without an agreement, and in that case, ask to the user to try again with some less restrictive constraints, if that’s possible.
Hardware failures
Also in the case that a codec negotiation can be agreed, it’s still possible that they can’t work properly due to hardware failures. These can happen for both broken or malfunctioning hardware, like a broken CCD sensor in a webcam, or outdated and unmaintained drivers.
But more specifically to WebRTC, it’s also possible an issue regarding hardware
encoders: due to reduction of costs, some of them can be incomplete or buggy on
their implementation for some specific modes or configurations, specially in
low-end or commodity devices, leading to some combinations that doesn’t work and
are difficult or impossible to detect and prevent in advance. For these cases,
some of them are already blacklisted on the browsers and libwebrtc library, so
they are using software encoding, that although less performant and more battery
consuming, they are warranted to work according to the codec specification, but
this is not always possible and usually needs to be tested and blacklisted in a
one-per-one basis, sometimes also by modifying the code of the WebRTC stacks
themselves.
During conversation
Now that we can be pretty sure that the connection is being properly stablished, maybe the issue is happening during it.
Sender
If the connection is done, but we can’t see or ear the other participant, we can think on an issue with the capturing devices. According to Jitsi documentation, this can be due to the capture devices are not present, or they are not activated (on some laptops you can actively switch the webcam on/off), they are not plugged in (only necessary for external webcams), or they are not installed (some devices require the camera to be installed first). Regarding audio devices and microphones, they could not be available (especially with desktop devices, a microphone is never actually integrated. Here you need an external microphone or headset, which you connect to the appropriate ports on your PC), they are not activated (on some laptops with an integrated microphone or headsets there is a switch to activate / deactivate the microphone), they are not plugged in (only necessary for external microphones), or they are not installed (on some old computers the microphone must be installed).
If capture devices are working properly, maybe they are muted and we didn’t know
it. This can happen in both ends, sender and receiver. Maybe sender has his
microphone muted or its volume input level very low, or their webcam can be
disabled (not only by the user or the operating system security policies, but it
can also be disabled by the computer BIOS
or UEFI, but also at hardware level!), or
it has a webcam cover or a sticker, or just simply user is covering the camera
with his own hand (that happened me A LOT on a speed-dating app I developed,
where users were doing it to cheat the system to see their date first and flag
the connection as failed if they didn’t like their partner, so they could move
to another one quickier…). One way to detect these situations, besides
checking if the tracks are muted, is to inspect them to see if they are
sending just only silence or close-to-silence values, or in the case of video
check if they are sending black or very dark frames (or very saturated ones, in
case they blocked the camera by putting a direct light pointing to it if trying
to cheat the system, but also it gets saturated due to the reflection of the
infrared emitters used by the face recognition systems) and notify the user
about that, in addition to provide extra feedback to the user like UI vu-metters
for audio, or sounds when changing video track state. In addition to that, it’s
also possible that the user has been muted by a room administrator, so in this
case if it’s not clearly shown to both participants (sender and receiver), it
can be due to a bug on our code, or a bad UI/UX design decission.
Receiver
On the receiver side, similar issues can happen. In addition of having the speakers muted or with a very low volume, it’s also possible to be using the wrong output device (like trying to use audio of a previously plugged TV, but not plugged anymore), or simply have the headphones disconnected, so there’s no audio output devices at all. To solve that, it’s possible to use some platform specific APIs to query both the volume and output devices and if they are properly pluged, in addition to provide extra feedback to the user similar to the sender side ones, like UI vu-metters for audio, or sounds when changing video track state.
Connection bandwidth
If that’s not the case, then the connectivity issues are part of the connection itself. Some very good tool in browsers to identify them (browsers are the canonical target platform for WebRTC, so you should always first test your connectivity issues with it, both with your official web client, or create an internal one for development purposes) are webrtc stats internals. This tool provides a set of graphs and statistics that shows all the current WebRTC connections in the browser and how are they behaving, regarding bandwidth usage, dropped frames or codec issues, between other stats.
Regarding connection bandwidth, it’s not so much an issue having a low bandwidth connection like having an unstable or unreliable network, since WebRTC will try to adapt to the network conditions, and an unstable one would provoque that it try to get higher qualities than the later available bandwidths. So from user perspective, it’s better to have an estable low bandwidth connection that provides a more homogeneous quality, than an unstable high speed one.
But obviously, low bandwidth has a limit also with stable connections. Take in account that exchanging the initial signaling information is about 4KB in size (less than half if send compressed, since SDPs are plain text and they compress really well), including all the ICE Candidates, but after that, a single generic audio track compressed with Opus codec can need about 70KB (like 20x more data) per second. A video track with a resolution as low as 320×180 pixeles can need 200Kb/s or more, while a 640×360 resolution would require 500Kb/s, and for 720p HD resolution we would need about 2.5Mb/s or more for each one of the tracks (and 4K HD streams can easily get up to 10Mb/s or more), so don’t expect to have 20 users using 4K on a server with 100Mbits/s upload and download. For a friends/small organization server, 1 Gbits/s will often be enough but for a serious server 10 Gbits/s is advisable. Several (or many…) bridges having each a 10 Gbits/s link are used by big deployments. In these cases it becames impractical to pretend to have a streaming session, since sending all the data would produce cuts in the stream all the time and add incresing delays over time, or the drop of data would decrease the quality beyond reasonable levels. So in some situations (specially the extremely limited ones), it’s better to think about if a (video-)conference it’s the best option, or consider other alternatives, like just a chat messaging system. You can still use WebRTC to send the chat messages without needing a centralized server by using DataChannel objects as transport layer.
If having a streaming is mandatory also for low bandwidth situations, it’s still possible to force usage of lower quality codecs. On video we don’t have too much options on extreme low bandwidth use cases, but for audio we can use μ-law and A-law algorithms, that provide toll calls qualities at about 8KB/s and are widely standarized. But if we need to go beyond regarding narrower bandwidths or improved quality, state of the art audio codecs like Lyra 2 by Google, EnCodec by Meta, or Satin by Microsoft, make use of neural networks to get CD stereo audio quality with bandwidths lower than 1KB/s, but they are experimental and browsers doesn’t provides native support for them yet, although there’s some third-parties work towards using them in WebRTC with WebAssembly.
Low-end devices
On low-end devices with a slow CPU or low RAM capacity can be affected by third party processes or services, where they can “steal” the resources and make the operating system (specially on Android) to kill our call process, forcing our app to try to reconnect. This can happens specially when an app doesn’t make use of the operating system CallKit, ConnectionService, or other similar calls integration or “do not disturb” APIs, or some other similar ones to let to know to the operating system and the other apps that we are currently in a call, so they can get and steal the access to the microphone and speaker when they receive an incoming call without the user allowing it, or on resources constrained systems they can also force the termination of our app.
Other way where low-end devices can be severely affected is by the number of participants, since the bigger a session is, the more streams they need to decode and more bandwidth they use. This can be somewhat alleviated in these cases by taking a more aggressive approach when reducing the number of streams that clients will receive and decode or about their qualities, or maybe using a different architecture for them like a MCU or an hybrid system like a XDN, so decoding and combined layout is being done on server side, reducing the clients bandwidth and CPU usage but increasing server costs.
Delays
In some cases, this kind of interruptions and other ones can lead to some delays on the streams too. They are not happening due to the streams networking themselves but due to the clients buffering, both in the receiver trying to play everything it receives at realtime pace without discarding outatime data, but mostly on the sender side by not discarding it and sending already outdated streaming info once the connection is restablished. This mostly can happens due to having the streams configured giving priority to quality over speed of transmission and delays, but also by using TCP connections instead of UDP, that’s recommended for realtime streaming but not always available due to network conditions and availability. Additionally, other solution that can be applied on receiver side is to check timestamps differences and try to match them on received info, both by discarding some outdated data, and by speeding-up the stream playback during some seconds until the timestamps of received data and local walltime matches.
Connection itself
In addition to these issues on the connection itself, others can arise during normal operation, like network temporal drops or cuts that provoque packets losses and resends, adding more pressure on network congestion protocol, and in the worst case forcing a full reconection of our application. Or just simply a change of connected network, for example from wifi to cell network when loosing coverture, or from one cell network to the next one when moving around the city. In this situations the best solution is to try to left WebRTC to notify us by using the negotiationneeded event, trying to make all the process the most automatic and transparent for us as developers as possible.
TL;DR - Checklist questions to do to ourselves
So, in short, the things that needs to be checked in order to identify the WebRTC connection issues are:
-
Environment
- Have we properly configured our development and/or execution environment?
- Does we have extensive unit, acceptance and integration tests coverage? Are the passing successfully?
-
Permissions
- Have we/the user provided permissions to the application itself to execute?
- Is WebRTC disabled in the platform by some user or company policy?
- Does the user have the correct permissions on the conference room application?
- Is application login kicking us out, and preventing us to connect?
-
Connecting
- Is networking enabled in the device?
- Does routers/cell networks allows to connect to them? Are there radio inhibitors or some policies that prevent us to connect?
- Are we connected to any network?
- Does the network requires us to register ourselves to access internet?
- Does the network itself have internet access at all?
-
Discoverability
- Is the discovery server up and running?
- Is it accessible by the client? Are networks, ports and DNS properly configured?
- Are both the discovery server and its client bugs free?
- Is the client trying to connect to the discovery server at all?
-
STUN and TURN servers
- Does we have some STUN / TURN servers? Are they properly configured? Are they up and running? Are they accessible?
- Have we properly configured the STUN and TURN serves in our clients, including the access credentials? Are they accessible by some other client tools?
-
Network infraestructure
- Are simetric NATs, or properly misconfigured NATs, being used by both parties?
- Is there any firewall configured for any of the peers, both in their devices or networks?
- Is there any government policy forbidding the app usage or blocking its network traffic?
-
Negotiation
-
Handshake timeouts
- Is generation of ICE Candidates too much time consuming? Are we using Trickle ICE, or has we forced it to be disabled?
- Has there been more delays for the ICE Candidates of some tracks compared to other ones?
-
Codecs negotiation
- Are we using a device with a custom WebRTC stack? Does it has disabled support for any of the mandatory codecs required for WebRTC full-compliant clients (VP8 and H264 video codecs, and Opus, PCMA and PCMU audio codecs)?
- Does both clients have some common codecs with compatible operation modes? Is any of the peers using Safari browser older than 12.1 (only had H264)?
- Have we set excesive restrictions in the codec configuration, incompatible with our camera/microphone devices? Did we set error handlers to detect them, and when ICE Candidates were consumed without an agreement?
-
Hardware failures
- Are devices in good state and working properly?
- Does hardware encoders have buggy or incomplete implementations?
-
Handshake timeouts
-
During conversation
-
Sender
- Are the sender audio or video tracks muted? Maybe done by the receiver or room administrator?
- Are sender capturing volume levels very low?
- Has the sender disabled the camera or microphone? Has it blocked them, maybe on purpose?
-
Receiver
- Are audio or video tracks muted? Are playing volume levels very low?
- Is it being used the correct output device? Is it correctly plugged?
-
Connection bandwidth
- Is the connection bandwidth lower beyond practical limits? Is it a stable connection?
- Is bandwidth enough for the desired quality?
- Is a stream needed at all? Maybe is it better to use a lower-bandwidth alternative? Maybe use some non-standard optimized codecs?
-
Low-end devices
- Is the device very constrained on CPU and RAM resources? Is our app requiring too much unneeded resources for itself?
- Are we using operating system APIs to notify our app is in an active call?
- Does have our call more streams than our device can manage and decode in realtime? Does our device have enough bandwidth to receive them?
- Are we using the network architecture most appropriate to our use case?
-
Delays
- Are sender or receiver buffering excessive data instead of discarding outdated one?
- Does streams transmission configuration prioritizes quality over delays?
- Are we using TCP sockets instead of UDP to send realtime streams data?
-
Connection itself
- Is the network connection getting cuts or temporal drops? Are we having packet losses and resends?
- Does have our networks changed during our app operation?
-
Sender
Comment on Twitter
You can leave a comment by replying this tweet.